
Breaking the High Cardinality Barrier
Leveraging the Synergy between Grafana Loki and Prometheus to Monitor High Cardinality Jobs

I recently wrote a blog post for Grafana about my experience using Grafana, Prometheus, Grafana Loki, and our my custom-built exporters to monitor high cardinality jobs. This is based on experience monitoring a 3000 node data lake and especially it’s data load process.
In the post, I explain how we were able to leverage the deep synergies between Loki and Prometheus to monitor the actual performance of jobs, allowing us to reduce cycle time for loads from 20 minutes to less than six minutes. By combining metrics with logs information, we were able to deeply understand where compute and memory were being efficiently used and where it was being wasted. This unlocked 40% savings on the cost of the cloud infrastructure supporting these stream jobs.
I go deeper into these two use cases and also highlight the job_exporter we built that leverages the symbiosis between Prometheus and Loki to break the high cardinality barrier. Our job monitoring journey started by implementing one-off solutions for Databricks and for Azure Data Factory. The learnings from these two implementations — and the need to extend to more platforms — led us to build a generic job_exporter that is easily extensible.
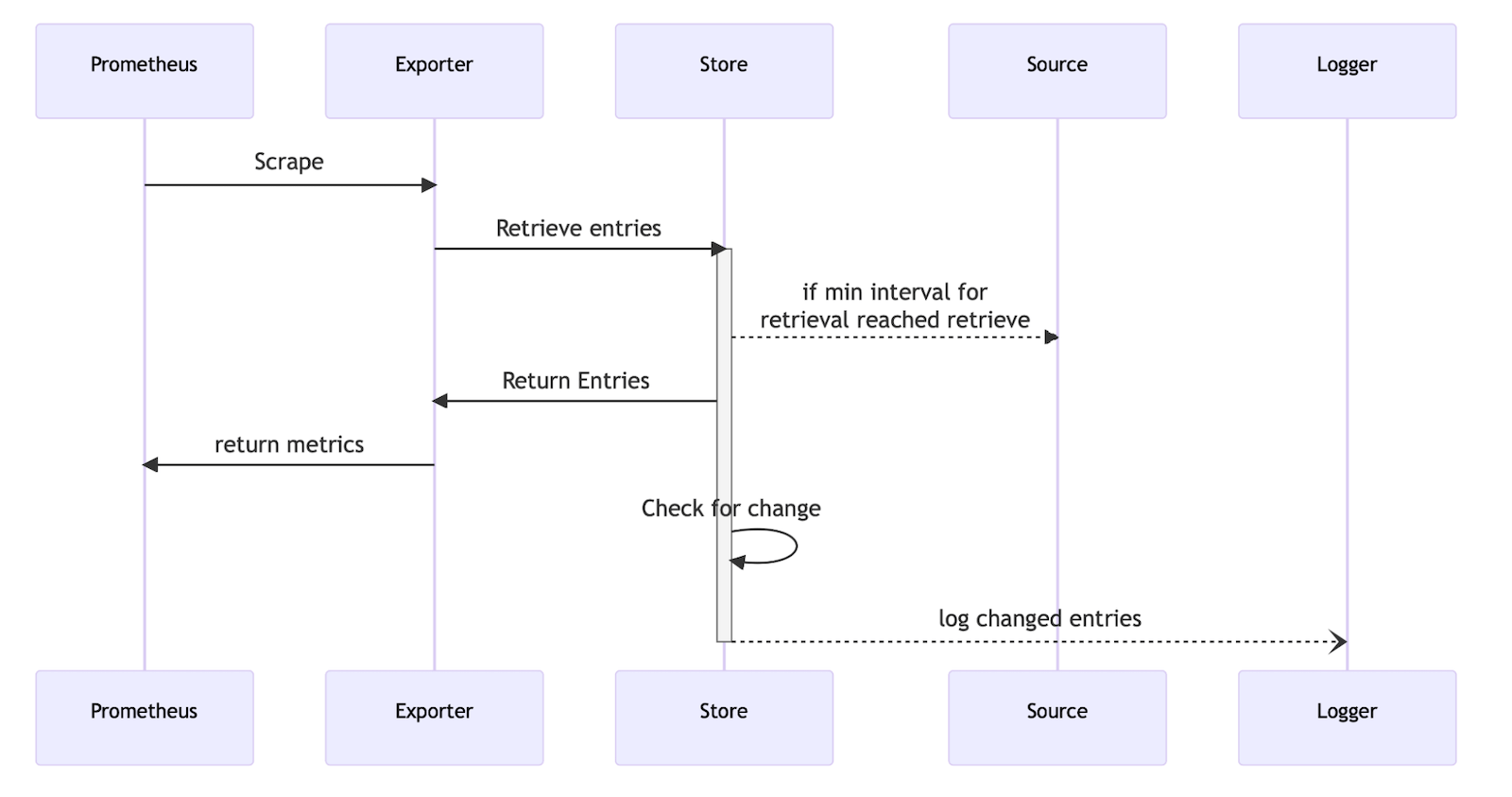
I hope my experience inspires you to look for what you can achieve by breaking the high cardinality barrier. Check out the full blog post on the Grafana blog to learn more:
https://grafana.com/blog/2022/12/02/monitoring-high-cardinality-jobs-with-grafana-grafana-loki-and-prometheus/